NoteChanges for Biden’s dropout
On July 21st, Joe Biden ended his campaign for re-election and Kamala Harris became the presumptive democratic nominee. The adjustments to account for Harris as the new candidate are appended to this article but the bulk of the methodology remains unchanged.
Introduction
To celebrate July 4th, I’m releasing a forecast of the 2024 presidential election, a rematch between Joe Biden and Donald Trump. Each day, the forecast simulates thousands of plausible election results in each state, the nation, and the electoral college. The output can be fully explored at the forecast’s homepage here.
Much like other outlets, such as FiveThirtyEight or The Economist, the forecast is the output of a statistical model that methodologically updates each candidate’s chances of winning as polls are conducted throughout the election cycle. Uniquely, all portions of the model follow the framework of Bayesian statistics, allowing for the mixture of prior beliefs with observed data while propagating uncertainty from each stage of the model to the next. Further, the model and surrounding data infrastructure are fully open source, from tip to tail. Everything from the data gathering pipeline, to the model code, to support for generating graphics found on the site can be found in the project’s repository on GitHub.
I encourage readers to explore the full codebase at their leisure, but for those who prefer plain-text language to thousands of lines of R and Stan code, a summary of the how the model generates the forecast follows below.
The past and future of presidential approval
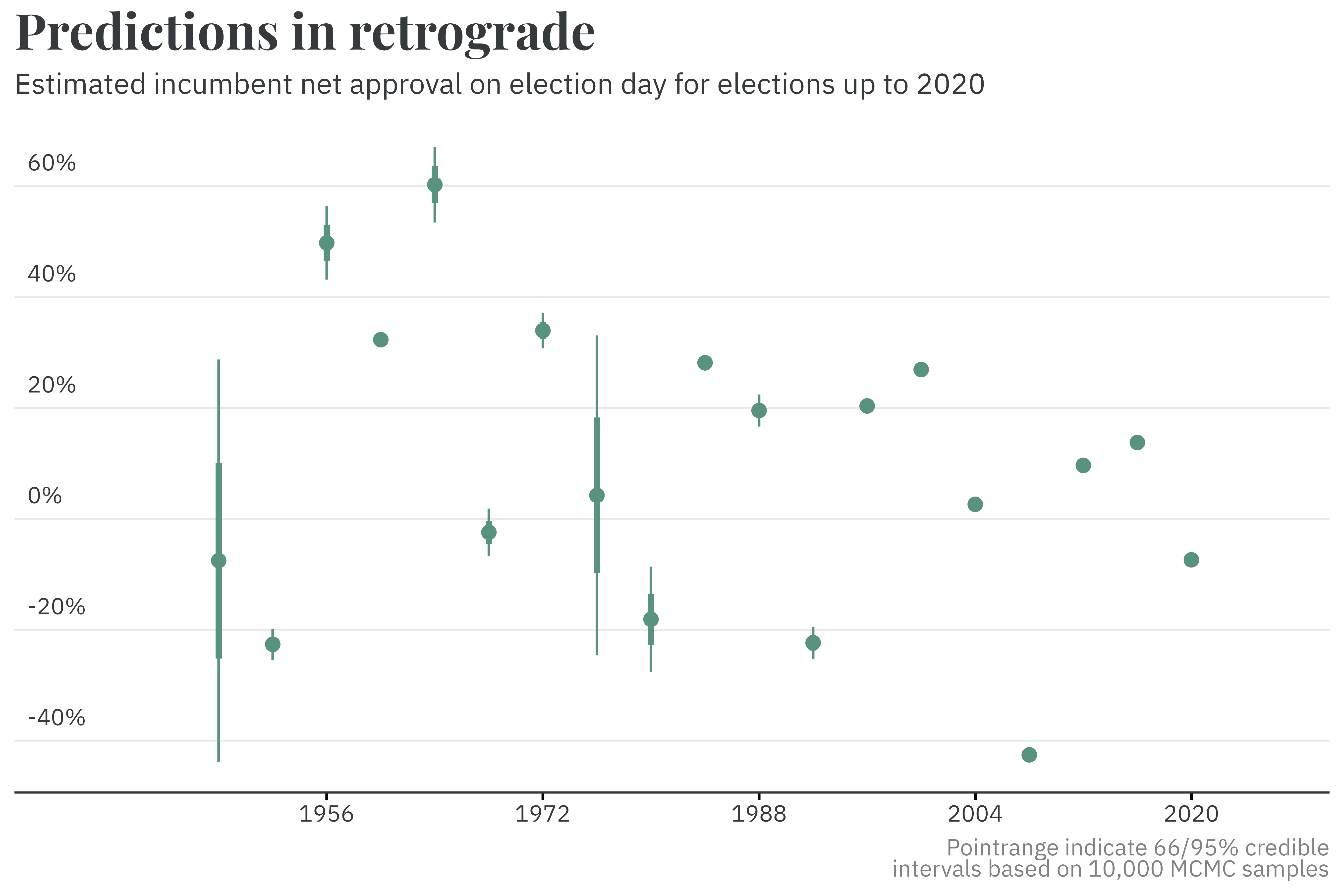
Rather than beginning with polls or other direct predictors of electoral success, the first step the model takes is to estimate incumbent presidential net approval on election day. Incumbent approval, in combination with other indicators like economic growth and partisan lean, can be used to generate a reasonable estimate of the outcome in the absence of polls. As such, the model first looks to estimate the net approval of presidents past, then applies the information it gleans towards forecasting Joe Biden’s net approval come election day.
In the past, presidential approval was polled less frequently than it is today. Net approval data from FiveThirtyEight’s historical averages shows, for example, days or even weeks-long stretches with no updates for mid-century presidents. To address this, a dynamic linear model is used to fill in the gaps. This type of model ebbs and flows to match changing approval over time while allowing uncertainty to grow during times of little-to-no polling. When there haven’t been any recent polls, the estimates for election-day approval are highly uncertain; when there is a flood of polling data, the estimates are highly precise.
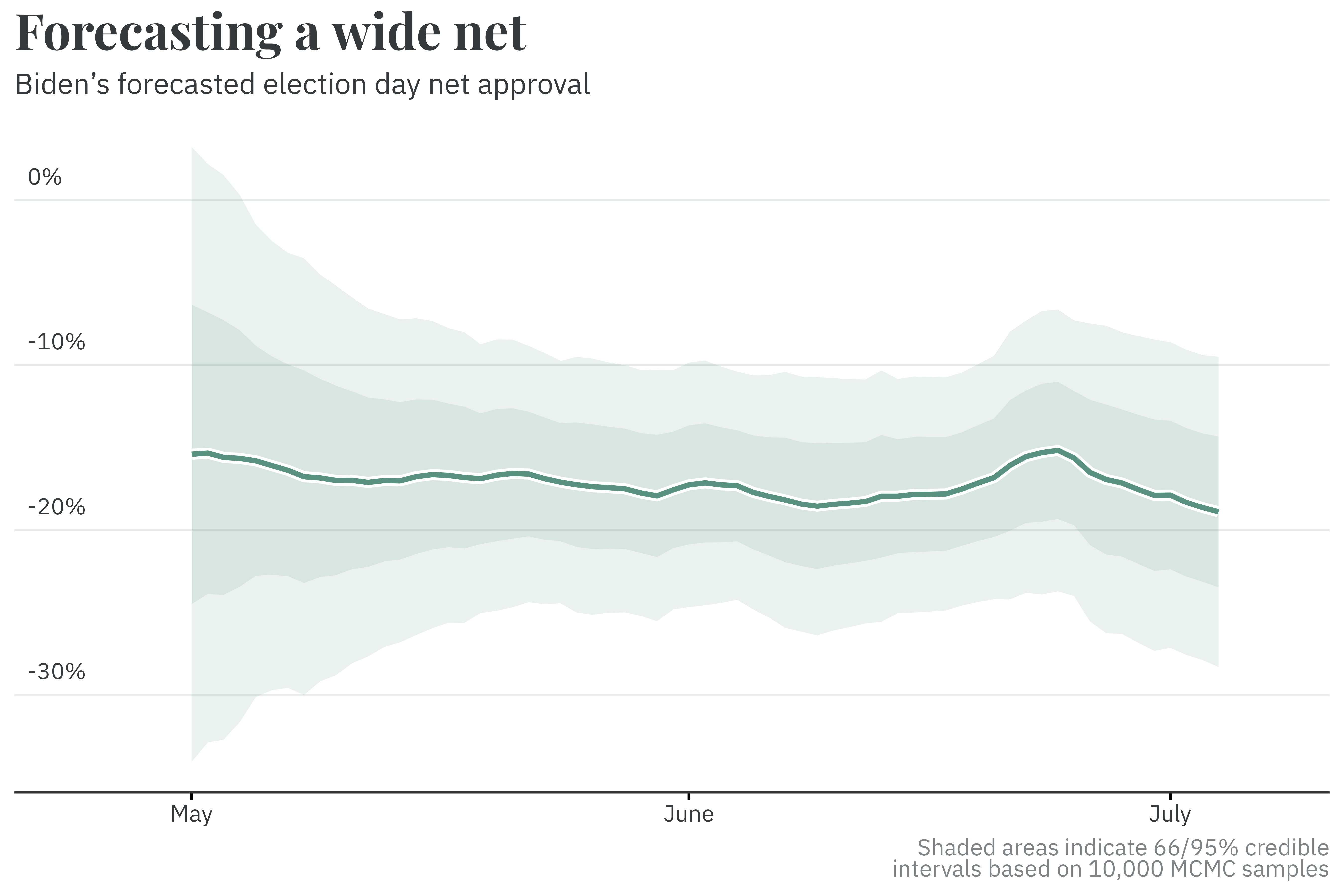
A similar method is used to forecast Mr. Biden’s net approval rating on election day. A dynamic linear model, having learned how net approval tends to change over the course of an election cycle, fills in the gap between Biden’s net approval today and election day, while accounting for the uncertainty inherent in the four month gap between now and then. At the time of this writing, Biden’s net approval is expected to land somewhere between -28% and -10% on election day. As we inch closer to election day itself, the uncertainty around the forecasted estimate will decrease.
Time for change
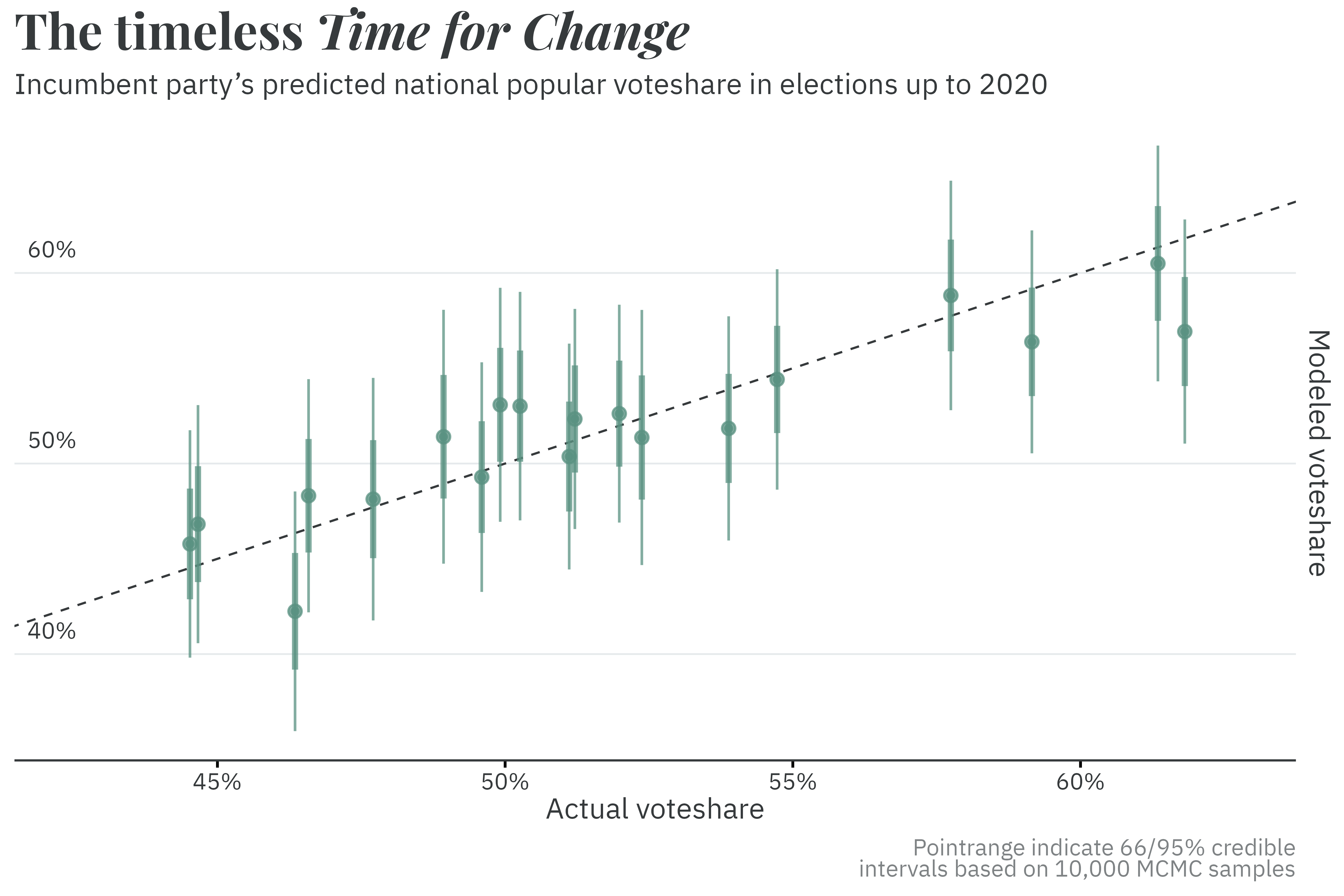
After having estimated Biden’s net approval on election day, the model is next tasked with using this information to estimate the results of the national popular vote. To do so, it employs a variant of a model first devised in 1988 by Dr. Alan Abramowitz, a political scientist and professor at Emory University, dubbed the Time for Change model. The Time for Change model predicts the incumbent party’s voteshare (excluding third parties) using only three variables: economic growth measured in the year-over-year change in real GDP, incumbent approval, and whether (or not) the incumbent president is running.
There have only been 19 presidential elections in the modern electoral era.1 With a small selection of training data, a model should necessarily produce uncertain, yet reasonable, predictions.2 This is certainly the case with the Time for Change model. Applied to the 2024 election, the Time for Change model expects Biden, the incumbent, to win between 42.7% and 54.9% of the national popular vote (conversely, it expects Trump to win between 45.1% and 57.3% of the national popular vote).
1 1948 is widely used as the starting point of the modern electoral era.
2 Be wary of models that claim to produce highly precise estimates with little data — they are likely overfit and unable to predict outside of the training set.
Partisan lean cuisine
As Al Gore and Hillary Clinton know all too well, winning the popular vote is not enough to become America’s next president. Candidates must win at least 270 of the electoral college’s 538 votes, which are awarded by winning in each state.3 To have a reasonable expectation of who the next president will be, reasonable estimates of the national vote are not enough — you need state-by-state projections.
3 As a further wrinkle, electoral votes are awarded by both state and congressional district in both Nebraska and Maine.
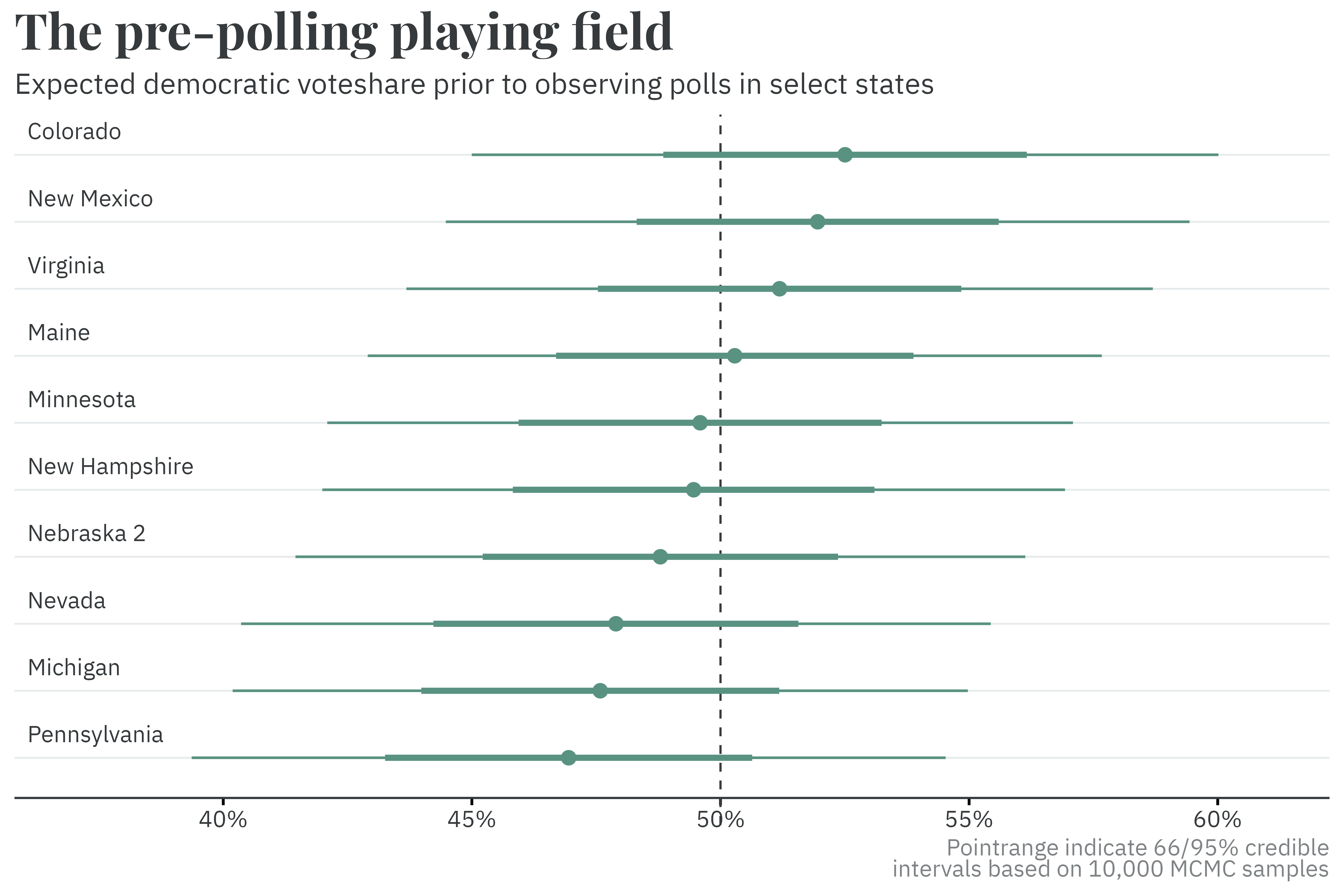
To generate these state-by-state projections, the model needs to estimate the partisan lean of each state. Partisan lean is simply how much more democratic or republican a state is relative to the nation as a whole. Having a partisan lean towards one party, however, doesn’t necessarily mean the state votes for that party. For example, in 2020, Joe Biden won 52.2% of the national two-party voteshare but only won 50.1% of the two-party voteshare in Georgia. The state voted 2.1% to the right of the nation, yet still awarded its 16 electoral college votes to Biden. Had Biden dropped in the national polls to only 51%, Georgia likely would have been won by Trump.
The model fits Cook’s Partisan Voter Index (PVI), an approximation of partisan lean based on how each state voted in the previous two election cycles, to the observed partisan lean in each state for elections up to 2020. It then uses 2016 and 2020 results to estimate what each state’s partisan lean will be in 2024. Simply adding the expected partisan lean in each state to the expected national popular vote yields reasonable state-by-state expectations. Notably, this is done prior to having observed any polling data, while maintaining and combining the uncertainty inherent to both estimations.
Poll vaulting to election day
With reasonable prior expectations for the voteshare in each state, the model can now start to incorporate polling data collected throughout the campaign. Not all polls, however, are created equal. As such, polls must meet a minimum set of criteria to be included in the dataset influencing the model:
The poll must include both Joe Biden and Donald Trump as named candidates. Biden and Trump are the nominees for the two major parties; polls that exclude either candidate do not represent the choice that voters will be making come November.
The poll must not include any hypothetical candidates, nor any candidates who have dropped out of the race. Michelle Obama, for example, is not running for president, yet sometimes appears as an option on presidential polls. This does not represent an actual choice voters will be presented with come November, so a poll that includes her should be excluded. For similar reasons, polls that include candidates like Ron DeSantis or Dean Phillips, who have both dropped out of the race, are excluded.4
4 A full list of allowed candidates can be found here.
5 A full list of banned pollsters can be found here.
Polls conducted by pollsters with a track record of shoddy methodology or a history of peddling conspiracy theories are excluded outright. This is not meant to exclude good faith pollsters who tend to produce results favoring one party or the other. Polling is an imperfect science, and pollsters with good methodology can still produce biased results. Pollsters who are unable or unwilling to engage in good-faith science, however, cannot produce modelable results, and are therefore removed.5
With eligible polls in hand, the model attempts to estimate the underlying support for each candidate in each state. Polls are assumed to be a combination of the true underlying voter preference and structural biases associated with the poll itself. For example, polls conducted via landline telephone vs. online panels reach very different types of people. By modeling the bias introduced by outreach mode or other poll characteristics,6 the model can, ideally, subtract out the bias, leaving only the true underlying voter preference.
6 Other poll characteristics modeled include: the pollster conducting the poll, the target population, and whether or not the poll was sponsored by a particular party
Similar to estimating presidential approval, a dynamic linear model is used to fill in the gaps on days where no polls are conducted. Between now and election day, the modeled trendline will tend to revert back to the prior expectations for the voteshare in each state. As we get closer to election day, there will be less time for this reversion to occur, and the forecast’s election day estimates will more closely match the polling data.
Even in states with little or no polling, the model is still able to detect shifts in public opinion, for several reasons. Firstly, the national popular vote is an aggregation of state-level voteshares, so shifts in candidate support nationally are propagated down through the states. Secondly, and more interestingly, state voteshares are modeled as correlated, allowing for shifts in one state to influence similar states. For example, Michigan and Wisconsin are demographically similar. If polls conducted in Wisconsin detect a 1% change, we can likely assume a similar roughly 1% change has occurred in Michigan, even if there have been no polls in Michigan to confirm. Conversely, states that are incredibly different, like Hawaii and West Virginia, have little effect on one another.
Once the model has estimated the election-day voteshare in each state, it simulates 10,000 plausible outcomes, from landslide victories to tightly contested races. In each simulation, the model adds up the total number of states and electoral votes won by each candidate. Each candidate’s probability of winning either the electoral college or a particular state is simply the proportion of simulations in which they emerge victorious.7
7 With the caveat that this model makes no attempts to model extremely unlikely events, like faithless electors or a successful January 6th-style coup.
Closing time
This model, for all the attempts to be as data-driven as possible, necessarily involves many individual choices which reflect the modeling preferences of the analyst,8 as all statistical models inherently do. This is not to say that the model is reflective of my personal political leanings. Rather, the specific choices I’ve made, like the variables to include in the state similarity calculation or the criteria used to filter polls, are different from other choices I could have made during the model’s construction. These alternative choices would necessarily have produced different, albeit, likely similar, results.
8 Me, in this case.
9 A list of forecasters I trust can be found here.
Other forecasters likely made different, reasonable, choices in the process of developing their models. Forecasting the outcome of an event months ahead of time is a difficult business, and there’s wisdom to be had in the crowd, so I encourage readers to view the output of this model in concert with other forecasts.9
The choices made in the construction of this model and the system around it were driven by a few fundamental ideals: the model should be built with transparent, open source software, produce accurate results, and honestly account for uncertainty throughout the modeling process. I believe these to be important goals to strive for and hope that the model I’ve put together has achieved them.
Unburdened by what has been
Following his disastrous performance in an early debate with Trump, Joe Biden announced on July 21st that he would no longer be seeking re-election and suspended his presidential campaign. Later that same day, he endorsed Kamala Harris. Since then, Harris has garnered support from elected officials across the democratic party and received enough pledges from party delegates to become the presumptive democratic nominee.
While much of the modeling architecture remains the same with Harris as the candidate, two slight changes are required to accommodate her stepping in as the presumptive nominee. Firstly, although she served in the incumbent administration, Harris herself is not the incumbent president. Thus, the output for the Time for Change model is based on a non-incumbent nominee.10 Secondly, polls of Harris and Trump are now used to update the model.11 In polls conducted prior to Biden dropping out, I include a parameter that adjusts for Harris as a hypothetical candidate. In post-dropout polls, however, Harris is modeled as the presumptive nominee.
10 This portion of the model is still based on the incumbent’s net approval rating, regardless of whether or not the incumbent is running, and therefore still uses Biden’s net approval.
11 Polls of Biden and Trump are still included as they still contain information on pollster biases, state correlation, and the rate that public opinion can change. The results of a matchup between Biden and Trump are simply not retained in the model’s output.
Citation
BibTeX citation:
@online{rieke2024,
author = {Rieke, Mark},
title = {A Forecast of the 2024 Presidential Election},
date = {2024-07-04},
url = {https://www.thedatadiary.net/posts/2024-07-04-forecast-methodology/},
langid = {en}
}
For attribution, please cite this work as:
Rieke, Mark. 2024. “A Forecast of the 2024 Presidential
Election.” July 4. https://www.thedatadiary.net/posts/2024-07-04-forecast-methodology/.