Reparameterizing multinomial models for better computational efficiency
bayes
stan
rstats
Author
Mark Rieke
Published
April 26, 2023
I tend to find myself modeling categorical questions with many possible options. Questions on patient surveys have multiple options to choose from and there can be many possible candidates listed on an election poll. If modeling in Stan, the multinomial sampling statement is a natural tool to reach towards first. Multinomial models in Stan, however, cannot be vectorized1, so they can be very slow in comparison with other models. This can be pretty frustrating! And throwing more computational resources at the problem can help, but (from my experience), only marginally.
1 Or, if they can, I am wholly unaware
2 Andrew Gelman et. al., “Bayesian workflow,” (November 2020), https://doi.org/10.48550/arXiv.2011.01808.
3 Richard McElreath. Statistical Rethinking: A Bayesian Course with Examples in R and Stan (Boca Raton, FL: Chapman & Hall/CRC, 2020), 363-365.
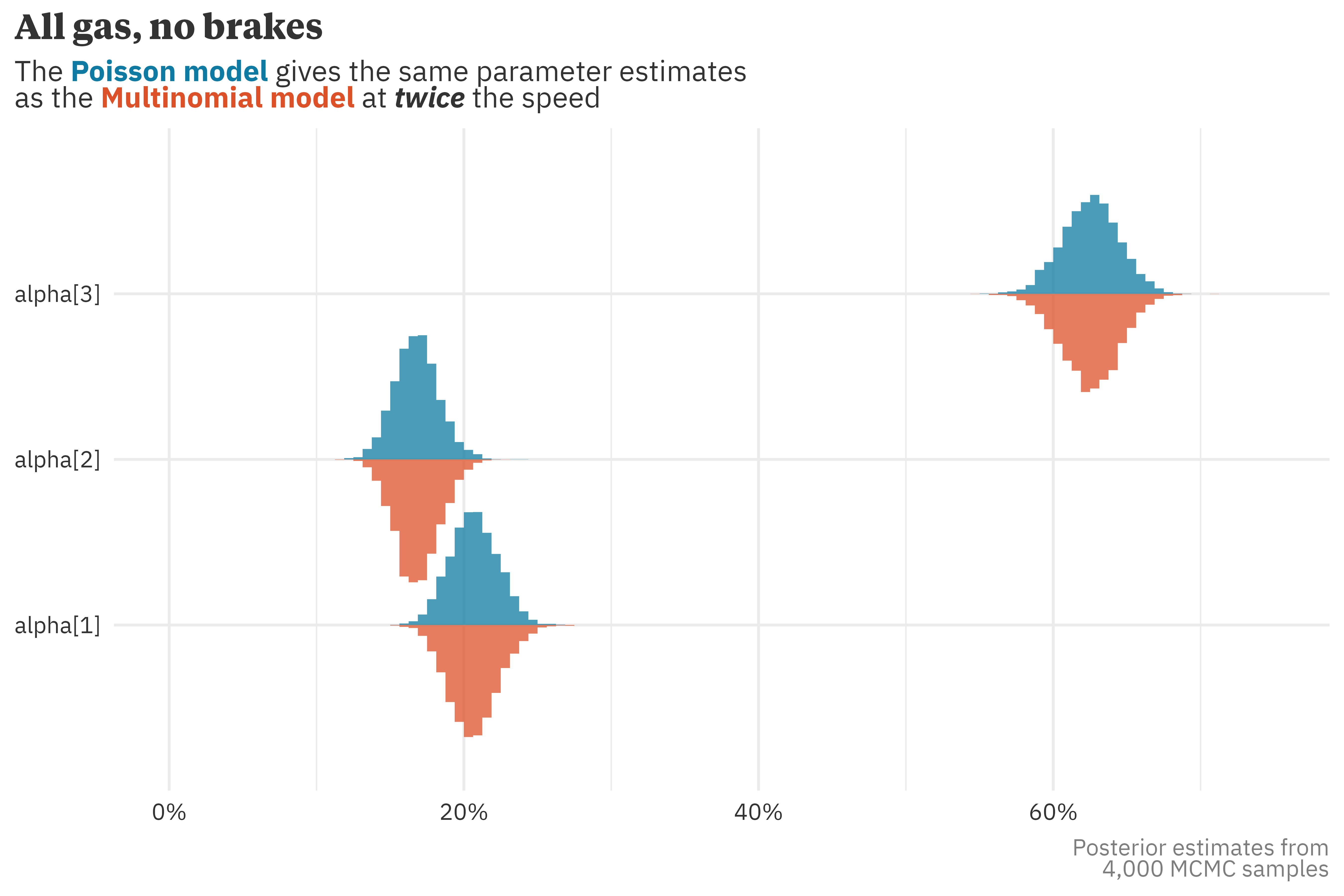
Andrew Gelman, Bayesian benefactor that he is, has quite a few thoughts on how to address modeling issues. My favorite and most oft cited of which is the folk theorem of statistical computing, which states that computational issues are more often than not statistical issues in disguise and the solution is usually statistical, rather than computational.2 Perhaps unsurprisingly, this advice rings true in this scenario — this computational conundrum has a particularly satisfying statistical solution. With some (in hindsight, pretty simple) mathematical wizardry, we can rewrite a multinomial as a series of Poisson sampling statements.3 In this case, we’re truly getting a free lunch — this reparameterization provides the same inference as the original parameterization at a far quicker pace!
To see this in action, let’s simulate some data and fit a few models. The code block below generates a multinomial response matrix, R, in which each row represents the number of respondents who have selected from three available categories.
Code
library(tidyverse)library(ggdist)library(riekelib)# fix category probabilities & simulate number of respondents per rowset.seed(40)p <-c(0.2, 0.15, 0.65)totals <-rpois(25, 25)# simulate responsesR <-matrix(nrow =3, ncol =25)for (i in1:length(totals)) { R[,i] <-rmultinom(1, totals[i], p)}R <-t(R)# preview the first 5 rowsR[1:5,]
This is a pretty simple model and doesn’t take too long to run, even with cmdstanr’s default of 4,000 samples. We can, however, do a bit better. Let’s refactor the multinomial with a series of Poisson likelihoods. To quote McElreath, this should sound a bit crazy. But the math justifies it! The probability of any individual category can be written in terms of the expected number responses for that category, e.g.:
\[
\alpha_c = \frac{\lambda_c}{\sum \lambda}
\]
The sum of the expected category values, \(\sum \lambda\), however, must equal the total number of respondents, \(N\), so we rewrite each category’s expected number of responses, \(\lambda_c\) in terms of the probability \(\lambda_c\):
\[
\lambda_c = \alpha_c N
\]
This is the same \(\lambda\) that we usually see in Poisson models — we’ll end up with a separate Poisson model for each possible category (three, in this case). The model can now be written for each row, \(i\), and category, \(c\).
This may feel weird — why did the sampling time decrease when we increased the number of sampling statements from one to three?5 It all has to do with vectorization! Stan’s poisson() statement is vectorized, whereas the multinomial() statement is not. This means that instead of looping over N rows in the dataset, we only need to loop over the 3 categories.
5 We did also add an additional multiplication step to convert from \(\alpha\) to \(\lambda\), but the bulk of the time is spent in the sampling.
6 In this toy example, the sampling time roughly halves. In larger, complex models I’ve built in practice, I’ve seen sampling times drop by 75% with a Poisson implementation.
I’d mentioned this before but it’s worth repeating: the benefits of vectorization truly are a free lunch! We get the same parameter estimates from both models at roughly twice the speed!6